
Edge computing has emerged from stealth-mode and judging from the amount of media coverage that it is generating has begun to attract interest for its application in mobile systems and the Internet of Things (IoT). One recent blog even asked whether edge computing could mean the end of cloud computing. A big question for IT architects is whether edge computing is an important architectural pattern, a niche product or just a vendor-driven diversion.
There is also much confusion around what edge computing is and does, which makes an evaluation of its impact more challenging. To further complicate matters, edge computing has been given multiple names – it has been referred to as the ‘edge data centre’, the ‘intelligent edge’, the ’edge node’ or just ‘the edge’.
The edge versus the middle
Discussion over where processing is best done in a system – at the edges, within the network or in a central data centre – is as old as IT itself. As far back as 1981, the “end-to-end principle” was used to justify keeping applications at the edge (in the end systems). In traditional telephone networks, the edge was the demarcation point where a customer’s telephone device connected to the telco’s physical infrastructure.
What the ’edge’ is has been the subject of increasing debate now that most systems are defined by software rather than physical hardware. The current discussion of edge computing has extended this debate through its wide variety of use cases. For example, a connected diabetes application that uses a smart glucose sensor could do sufficient processing to control an insulin pump while also selectively forwarding event data to a cloud-based application. Depending on the device specifications, the ’edge’ could be in the sensor (meter) itself, in the pump, in a nearby smartphone or even in a local cloud; the edge is not always a physically or logically fixed point.
The rationale for edge computing
The ICT industry has seen several swings between centralized and distributed models – starting with the shift from mainframes to PCs and servers in the 1980s; moving to the consolidation of servers into server farms in the 1990s; and then swinging back to the centralization of corporate data processing in cloud architectures and within public cloud provider facilities in the 2010s. Edge computing is the latest swing of the pendulum as it represents a shift away from exclusively using cloud resources to the distribution of the services closer to where the physical and digital worlds meet (i.e., where the data is generated).
Edge computing responds to requirements for low latency and high resilience. Connected vehicles, for example, cannot wait for a remote cloud application to respond over a “best efforts” wireless Internet. Accidents can happen much too quickly!
Edge computing can also reduce data transport requirements, thereby saving network bandwidth costs and avoiding data storage proliferation. A Content Distribution Network (CDN) is one example of how performance and efficiency can be improved by storing content closer to its users.
Edge computing can also be modelled as an extension of the cloud by delivering services from whichever location meets performance requirements: edge services for speed and timeliness combined with central cloud services for large-scale data analytics and management. One example would be an enterprise cloud service that trains a machine learning model, then serves the latest model at the edge. One key to ensuring consistency between cloud and edge application deployments is the adoption of cloud-native technologies for the edge node. For further discussion of the cloud extension approach, see this NewStack article.
Comparing edge computing to cloud, fog and mist
The effort to define new technologies – what they are, what they do, where they can be used and their benefits – is a familiar and ongoing practice. Edge computing is no exception to this rule and the attempt to define its scope and range of applications may be an indicator of its importance, but ‘edge’ is also becoming one of those fuzzy terms that will eventually become meaningless.
HPE says the Intelligent Edge refers to “the analysis of data and development of solutions at the site where the data is generated. By doing this, intelligent edge reduces latency, costs, and security risks, thus making the associated business more efficient. The three major categories of intelligent edge are operational technology edges, IoT edges, and information technology edges, with IoT edges currently being the biggest and most popular.”
Similar definitions have been proposed by the National Institute of Standards and Technology (in their draft definition for Fog Computing), the Open Fog Consortium, the Institute of Electrical and Electronic Engineers (IEEE 1934), the European Telecommunications Standards Institute (ETSI Multi-access Edge Computing), the Open Edge Computing Initiative and the ISO/IEC.
The State of the Edge 2018 glossary lists a variety of edge-related terms including device edge, device edge cloud, edge cloud, edge computing, edge data center, edge node, edge-enhanced application, edge-native application, fog computing, infrastructure edge and cloudlet.
Despite these efforts, there are as yet no approved standards for the concepts and functions of edge computing; the descriptions are often driven as much by marketing and competitive positioning as by the technology itself. Edge computing can be a mini-cloud/cloudlet (i.e., a distinct system that connects on a peer-to-peer basis); a logical extension of a cloud infrastructure (i.e., a unified cloud-based distributed system); an edge-based container platform (i.e., integrated software operating across multiple infrastructures); or simply a smart attachment (i.e., a smart sensor/actuator). A unified theory of Edge Computing is not yet available!
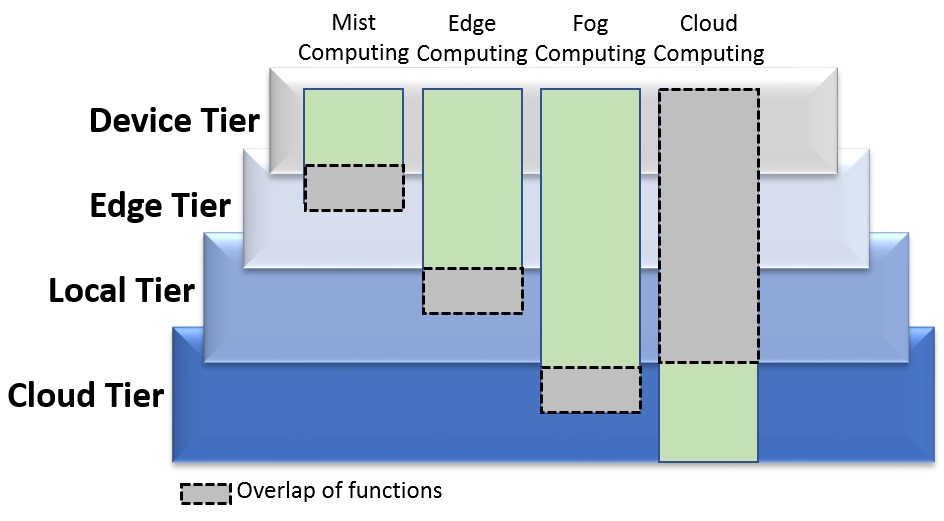
One area that would profit from further clarification is how edge, fog, mist and cloud computing relate. Edge computing is commonly considered to be the node closest to the physical/digital interface, with cloud computing being at the other end. The diagram below identifies four tiers – the device tier (sensors, actuators, smartphone), edge tier (processing node ‘close’ to the edge, including AI), local tier (building aggregator/orchestrator/local cloud, or a car system interface, or a factory level processor) and cloud tier – and positions mist, edge, fog and cloud computing across these tiers. Edge computing, for example, refers to nodes in the device and edge tiers with some overlap into the local tier.
Edge Computing products
Terminology is only one small step in the technology development process. Active product innovation, market competition and investment in new products are all signs of customer demand and are indicators that the technology meets user needs. HPE, for example, recently announced an investment of US $4 billion over the next four years to accelerate the development of its Intelligent Edge.
The major cloud service providers either have or are testing edge computing offerings. Microsoft Azure IoT Edge, introduced in 2017, acts as an extension of the Azure cloud environment to the edge. Although not specifically called an edge system, Azure Stack provides an “edge” for private data centres. Amazon AWS Lambda@Edge executes user code at AWS locations around the world, closer to the end user, and Amazon CloudFront is its global content delivery network. Google IoT Edge, currently in alpha status, intends to bring data processing and machine learning to edge devices that can run Android Things or a Linux-based operating system. Google is going further into edge computing with its Edge TPU hardware to support AI at the edge. There are many edge-related products emerging from other vendors including networking companies (e.g., Cisco, AT&T), industrial automation companies (Schneider Electric, Siemens, GE) and software vendors (SAP, Oracle).
Why is edge computing important?
The recent InsightaaS Great Canadian Data Centre Symposium highlighted the benefits and uses of edge computing. Panelists in the Computing at the Edge session argued that edge computing would basically be implemented through micro-data centres (a data centre-in-a-box) with applications executed where it is most appropriate. Wilfredo Sotolongo, VP and GM, Lenovo DCG Internet of Things (IoT) Group stated that, while most of today’s edge systems are being built from current technology, new designs are coming. Herb Villa, senior IT systems consultant with Rittal Corporation, suggested that the edge is where the separate worlds of IT and OT (Operational Technology) get together and that edge computing is especially useful for integrating security across the whole environment. He used New York City’s transit system as an example of an intermittently connected system that would be a good candidate for edge processing.

The panel also identified IoT as a major driver for edge computing, perhaps even its “killer app.” For example, edge IoT data could be used to fuel AI-based predictive maintenance applications. Sensor data can be analyzed, allowing detailed monitoring and alerting only when failures are on the horizon. The efficiency, scale and diversity of IoT argues strongly for functional distribution of processing closer to the network edge.
Edge computing may represent just another swing of the IT systems pendulum and a natural evolution of the hybrid cloud model. The role of edge computing in the transformation of ICT to ubiquitous computing has yet to be fully developed but interest in its progress and its applications is growing rapidly – whether interest equals importance remains to be seen.






{kind=link}