
If software is eating the world, storage is the ‘pantry’ for both software and the data it depends on. Storage, however, is often viewed more as a necessary evil – unappreciated but still essential (after all, data must be stored somewhere!).
But digital transformation, which is now well underway in many enterprises, is forcing a re-thinking of what, where, when and why data needs to be stored. The key digital technologies – artificial intelligence, social networks, cloud computing, the Internet of Things (IoT) and Blockchain – either generate large volumes of data or depend on access to stored data.
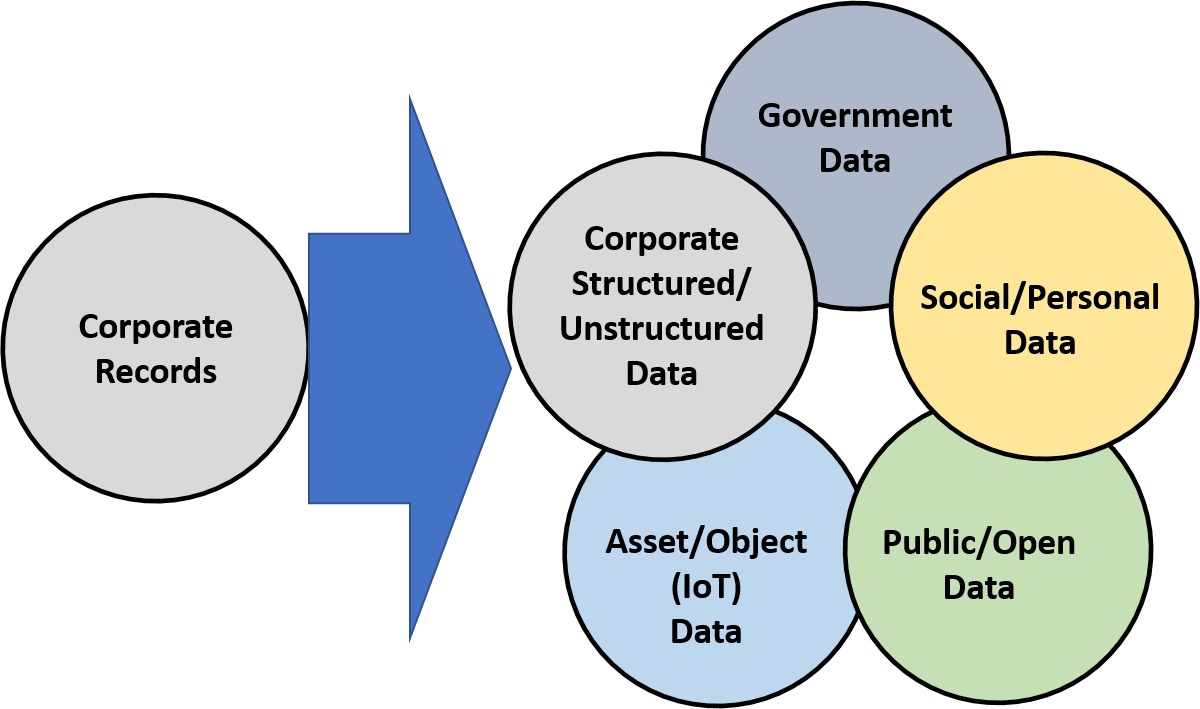
Everyone who searches on the Internet knows that finding data can be like playing Where’s Waldo? – there can be no doubt that data storage is widely distributed. Two important questions for organizations planning digital transformation are: why is distributed storage necessary for digital transformation, and why is managing distributed storage assets important to the business?
The state of storage today
For the past 50 years, most critical data has been stored centrally, in “safe” repositories in locations such as on-premise data centres. Even the evolution of computing from mainframe to client/server to desktops and smartphones has not fundamentally changed how enterprise data is treated. The IT department has been the custodian of the data and is charged with protecting and controlling stored resources on behalf of the data owners.
Centralized storage models, however, are beginning to break down now that useful data is being generated by almost everything from the smallest sensor to the largest cloud service. There is no limit to how much storage will be needed in the next few years. A recent report developed by scientists at the University of Southern California states that more than 295 exabytes of data existed in 2011 (an exabyte is 1,024 petabytes, a very big number!), with an annual growth rate of 23 percent. Another recent article claims there are 2.7 zettabytes (1,024 exabytes) of data in the digital universe and, as an example of growth rates, at least 3.3 million Facebook posts per minute alone.
Cloud computing is also changing storage practices, since cloud-based storage is now available from virtually every cloud provider. The RightScale 2017 State of the Cloud Report indicates that 85 percent of those surveyed have a multi-cloud strategy, with applications running in an average of 1.8 public clouds and 2.3 private clouds. Even cloud storage can no longer be neatly centralized in a single cloud location!
Another complicating factor is that not all the data is enterprise owned. Multi-sourced data – the combination of enterprise data with external, third-party data sets – can produce valuable insights for improved decision-making, for accelerating innovation and, ultimately, for generating competitive edge. Combining weather information with data from road sensors to predict traffic delays is one simple example. Another is merging birth rates with disease data to estimate medical demands. But since it’s hard to predict data requirements for future innovations, the default is often to store and retain everything.
Systems have grown in complexity from the 1970s to the present and their storage models have evolved along with demand for processing.
Storage services evolution

Storage devices have evolved from the primitive punch cards and large tape drives of the 1960s to the Solid State Drives (SSDs), high capacity cartridge tapes and USB drives in use today. Moore’s Law has allowed massive increases in physical capacity – for example, hard drives have expanded from 3.75 megabytes in 1956 to 14 gigabytes in 2017. Early storage systems were very difficult to distribute, but it is now common even for a smartphone to have 128GB of storage, a level of capacity that was unheard of just a decade ago.
The ongoing migration to cloud computing has been hindered by the perceived loss of control over where data is stored as well as by increasing concerns about data security and privacy. However, cloud storage services can also create new opportunities. For example, blockchain-based systems have drawn attention to distributed ledger storage.
Radical new storage technologies, currently in the research stage, may provide the disruptive change needed for future mass storage requirements. DNA storage, according to an MIT Technology Review article, aims “to exploit the molecular structure of DNA. Researchers have long known that DNA can be used for data storage—after all, it stores the blueprint for making individual humans and transmits it from one generation to the next. What’s impressive for computer scientists is the density of the data that DNA stores: a single gram can hold roughly a zettabyte.” Researchers in Italy have designed and tested a DNA storage system based on bacterial nano-networks. The surprising answer to “Where’s Waldo?” for data may someday be that it’s inside the bacteria.
Cloud storage now offers alternatives to traditional on-premise storage devices. Storage-as-a-Service offerings, such as Dropbox, and infrastructure services, such as Amazon S3, now enable virtually unlimited storage capacity, with most of the physical maintenance details hidden from the user. Cloud storage services can also be matched more dynamically to their intended use – keeping records for a short term, for example, or storing unstructured blocks of data to long-term archival retention.
Recently, the Cloud Native Computing Foundation (CNCF) announced an open source software-defined storage project based on Rook. According to the github description, “Rook is an open source orchestrator for distributed storage systems running in cloud native environments. Rook turns distributed storage software into a self-managing, self-scaling, and self-healing storage services. It does this by automating deployment, bootstrapping, configuration, provisioning, scaling, upgrading, migration, disaster recovery, monitoring, and resource management. Rook uses the capabilities provided by the underlying cloud-native container management, scheduling and orchestration platform to perform its duties.” This seems like a very impressive step forward from basic disk arrays.
Distributed storage challenges
One of the biggest challenges for storage systems is to store Big Data. Discussions of Big Data often reference a list of descriptors that all start with a ‘V’, which also must be addressed by storage systems. One set of V’s, described by Bernard Marr in a LinkedIn article, are:
Volume – the amount of data to be stored; storage expansion is continuous and accelerating with no apparent end; however, not all data can or should always be stored in the same location
Velocity – the speed at which the data is collected, transferred and analyzed; processing all the data can be a challenge for systems that may involve realtime control decisions
Variety – a measure of the types and formats of data to be handled; multimedia services include various combinations of voice, video, photos, email, messages, scans, sensor readings, alarms, location data, and more. Storage device characteristics can vary, and distribution may require orchestration of data across multiple locations
Veracity – refers to the validity and trustworthiness of the data; security, privacy, integrity, reliability, source certification and acceptable use all present challenges both within and among enterprises, especially when storage of linked data is required
Value – always a consideration when potentially expensive IT resources are involved; data must be worth storing, especially when archived and not used frequently. Knowing what data is valuable and where to store it is a challenge.
There are, of course, many other technical considerations. For example, using a mix of solid state drives, removeable storage, locally-attached hard drives, network-based hard disk arrays and bulk tape storage can present compatibility and performance challenges. When augmented and virtual reality become widespread, physical objects will be closely aligned with their data object proxies, which may move with the physical objects, much like a smartphone today moves with its human user.
The bottom line
The next generation of storage systems for digital transformation will need to be capable of addressing the needs of data-intensive applications, widely distributed, inter-connected and integrated. Storage is now and will be widely distributed across multiple owners and will function as a fundamental platform component for the ecosystem (much like networking is today). In this environment, data storage cannot be fully centralized.
Distributed data must also be managed effectively to avoid massive duplication, to optimize accessibility and findability, and to ensure equal levels of protection and safety across many different environments. Without distributed storage management, it may be difficult to ever find Waldo!






{kind=link}